
If you've gone looking for guidance on assessing AI risk and setting tolerance, you've hit the same wall a lot of GRC teams describe: most AI governance frameworks stop at policy, or they're written for the people building models, not the teams deploying AI inside real business processes. They tell you to "maintain residual risk within tolerance" and leave you to figure out what that actually means on a Tuesday when a business unit wants to turn on a new AI tool.
This blog is a practical way to address that gap. A taxonomy you can actually use, and a way to set tolerance, KRIs, and KCIs that holds up for systems that behave probabilistically.
But first, a shortcut for the most common case. A lot of "deploying AI" really means bringing in third-party AI tools and agents, which makes this a third-party risk problem before it's anything else.
That's exactly what we built Conveyor's TPRM agent for, and it's free. Upload a vendor's SOC 2 and the agent does its own research, flags evidence-based risks, and hands you a draft assessment in minutes, so your team spends time on judgment calls instead of data entry. As Reed Loden, Head of Security & IT at HEX, put it: "assessments that used to take three to four weeks now come back in hours."
1. Start with a taxonomy you can actually use
Don't invent a parallel risk universe for AI. Start with your existing enterprise taxonomy and extend it with the failure modes that are specific to AI. Four buckets cover most of it:
- Data risks — exposure of sensitive inputs, retention you didn't sign up for, and whether your prompts or data are used to train someone else's model.
- Model behavior — hallucination, accuracy drift over time, and bias in outputs.
- Security — prompt injection, data poisoning, adversarial inputs, and model theft.
- Operational and compliance — explainability, regulatory exposure, and what the vendor actually commits to contractually.
Then tag every use case along two axes: how sensitive the data it touches is, and how much autonomy it has over a decision. That single cut routes most of your assessments before you write a control. A model summarizing public docs with a human reading every output is low/low. A model auto-approving transactions on regulated data is high/high and should never clear the same lightweight path.
When the AI is a vendor's, turn the taxonomy into questions you ask them directly: Does the product use AI, and where? Do they build their own models or rely on a third-party provider (and who)? Is your data used for training, and can you opt out? How do they test for bias and accuracy? We keep a running list of these — see 4 vendor security risk assessment questions to ask companies using AI and the Top 15 AI security questions showing up in B2B reviews — to build your intake set.
2. Set tolerance dynamically, not in a static statement
A one-time "risk tolerance statement" doesn't survive contact with a probabilistic system, and qualitative red/yellow/green heatmaps hide what's actually moving. An AI control that was green at launch can quietly go yellow as the model, the data, or the usage pattern shifts.
So anchor tolerance to consequences leadership already cares about. Business outcomes like revenue, risk and cost savings. We're talking dollars, regulatory exposure, customers affected, things like that. Then make it dynamic. Tie the threshold to model performance, not to a date on a policy doc. If a model drifts a couple of points in accuracy, your loss exposure can move fast, which means the line that says "acceptable" has to move with it. Practically: set a baseline at deployment, define the deviation that forces a re-review, and write down what happens automatically when you cross it (throttle, add a human, or roll back).
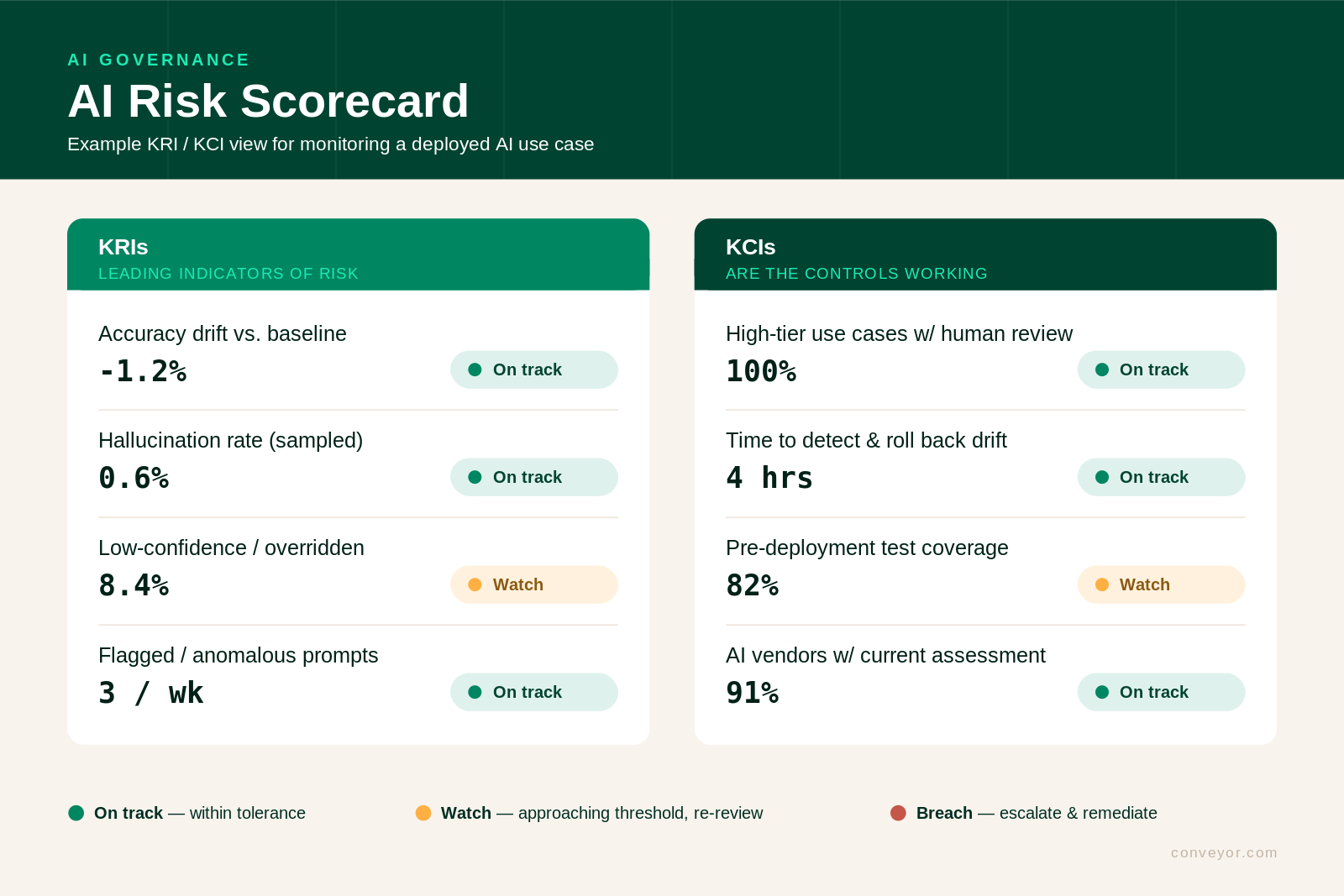
3. Pick KRIs that predict harm and KCIs that prove control
KRIs (leading indicators of risk):
- Accuracy and drift measured against the deployment baseline
- Hallucination / fabrication rate on sampled outputs
- Volume of low-confidence or human-overridden outputs
- Flagged or anomalous prompts (a signal of injection attempts or misuse)
KCIs (are the controls actually working):
- Percentage of high-tier use cases with human review in place
- Time to detect and roll back a drift or incident
- Coverage of pre-deployment testing across your use-case inventory
- Percentage of AI vendors with a completed, current risk assessment
The pattern that works: KRIs tell you the system is moving toward a line, KCIs tell you the brakes still work. Review them on a cadence and on triggers. Such as a model version change, a new data source, or a new way the output gets used.
4. Put residual-risk sign-off where it belongs
One more thing people usually get right: residual-risk acceptance shouldn't land on a single product owner. Systemic risks like data poisoning and algorithmic bias create enterprise-level liabilities that a business-unit manager doesn't have the mandate to accept. Route sign-off to the level that can actually own the consequence, and reserve a bright line for the things you simply won't do. Things like fully autonomous decisions on regulated outcomes, or sending sensitive data to a vendor with no contractual protection.
What "good" looks like in practice
The reason to get this right is the business impact it can have. It's what happens when AI and a tight review process work together on risk-sensitive work. Zapier's three-person GRC team is a good example.

By pairing an AI agent with human review, they cut the share of work needing a human from 90% to 20%, spend 75% less time, and tripled capacity with no added headcount and kept accuracy high. As their GRC lead Annie Stankiewicz put it, "it's comforting knowing that the AI isn't going to give me an answer that doesn't make sense." That's the KCI in action: the human is the final quality layer, not the data-entry clerk.
It's also worth separating two things GRC teams often conflate. Your internal compliance program and the way you prove trust to others are different jobs. Read Your GRC Program Is Solid But Your Buyers Don't Trust It for more on that. AI risk assessment lives at that seam: you're governing what you deploy and evidencing it to the people who depend on you.
The teams getting this right aren't the ones with the fanciest scoring matrix. They classified their use cases, agreed on a few bright lines, made re-assessment routine, and let an agent handle the busywork so people spend their time on judgment.



